Building a Safe Egress Layer for LLM Apps With HTTP Policies DNS Controls and Edge DLP
Jamie
Why “safe egress” is the missing security layer in LLM applications
LLM apps don’t just ingest sensitive data—they also emit it. Prompts, retrieved context, tool outputs, embeddings, log events, and even error traces can leave your environment through dozens of outbound paths: model APIs, plugin calls, webhook destinations, analytics SDKs, package updaters, and “helpful” auto-integrations added by teams under deadline pressure.
A “safe egress” layer is the set of controls that governs outbound traffic from your LLM runtime and its adjacent services. Its goal is simple: prevent data leaks and stop shadow integrations without relying on developers to remember every rule. Done well, it becomes a default-safe envelope around agents, RAG services, and internal automations—especially when those workflows can call tools dynamically.
The two failure modes to design for
1) Data leaks through legitimate outbound calls
Most leaks are not dramatic breaches. They’re small, repeated exposures: a customer email address in an error report sent to a SaaS logger; a snippet of proprietary code pasted into an LLM “debug” prompt; a full document chunk shipped to a summarization endpoint when only a redacted excerpt was needed.
LLM apps amplify this because they encourage dumping context to “help the model,” and because tool execution can turn a single prompt into multiple outbound requests across different providers.
2) Shadow integrations that quietly expand your risk surface
“Shadow integrations” are outbound connections you didn’t intend to approve: a new plugin endpoint, a secondary model vendor, a feature flag SDK beacon, or an employee adding a “temporary” webhook to make a demo work. They often bypass procurement, privacy review, and vendor risk assessment—yet they still carry real data.
Principles for a safe egress architecture
Before picking tools, align on a few principles:
- Default deny for outbound destinations, then explicitly allow what the app needs.
- Identity-aware egress: policies should depend on service identity (workload, tenant, environment), not just IP ranges.
- Layered controls: HTTP policies, DNS controls, and DLP each catch different classes of mistakes.
- Auditability: every allow/deny decision should be observable and attributable.
- Least data: even when egress is allowed, minimize what leaves (redaction, truncation, field-level filtering).
Layer 1 HTTP egress policies to control where agents can talk
HTTP egress policies are your main enforcement point because most agent “tools” and integrations are HTTP calls. The goal is to make outbound connectivity explicit, reviewable, and environment-specific.
What to restrict
- Destination allowlists by hostname and path patterns (not just domain-wide wildcards).
- Methods (e.g., disallow PUT/DELETE unless needed).
- Headers and auth patterns to reduce token exfiltration risk (e.g., block unexpected Authorization formats).
- Request size limits to stop “accidental bulk export” of long context windows.
- Per-tenant routing when multi-tenant apps must keep customers isolated (different keys, different endpoints, different logging sinks).
How to structure policies so they survive real teams
- Separate policy from code so approvals don’t require redeploying the agent.
- Use environment tiers: dev can be more permissive but still logged; prod is strict allowlist.
- Make exceptions time-bound (auto-expire demo endpoints).
This is where an edge platform with strong policy primitives becomes practical. Teams often standardize egress control and logging through a single connectivity layer so that new LLM tools inherit controls by default. Cloudflare’s broader platform approach can fit this model when you want security enforcement close to the network edge, rather than scattered across individual services. For reference context on the platform itself, see cloudflare.com.
Layer 2 DNS controls to stop unknown destinations early
DNS is a powerful “early choke point.” If a runtime can’t resolve a hostname, it can’t call it. DNS controls also catch cases where outbound traffic isn’t easily proxied through your HTTP policy layer (for example, libraries that resolve and connect directly).
Key DNS protections for LLM environments
- Domain allow/deny lists for categories that should never be reached from production (pastebins, consumer file sharing, unknown AI endpoints).
- Newly registered domain blocking to reduce risk from typo-squats and short-lived exfil domains.
- Internal-only resolution for sensitive internal services, so they are not accidentally addressed over public DNS.
- Split-horizon policies so the same name resolves differently by environment or tenant, supporting isolation.
Don’t forget DNS logging and review loops
DNS logs are a high-signal way to detect shadow integrations: you’ll see new destinations appear before anyone files a ticket. This is also where teams can accumulate “feedback debt” in security operations—repeated requests to allow new endpoints, similar exceptions, and duplicated approvals across groups. If your organization struggles with tracking repeat requests across channels, the pattern is similar to product teams dealing with duplicate customer asks in Feedback Debt and How to Spot Duplicate Requests Across Support Sales and Forums.
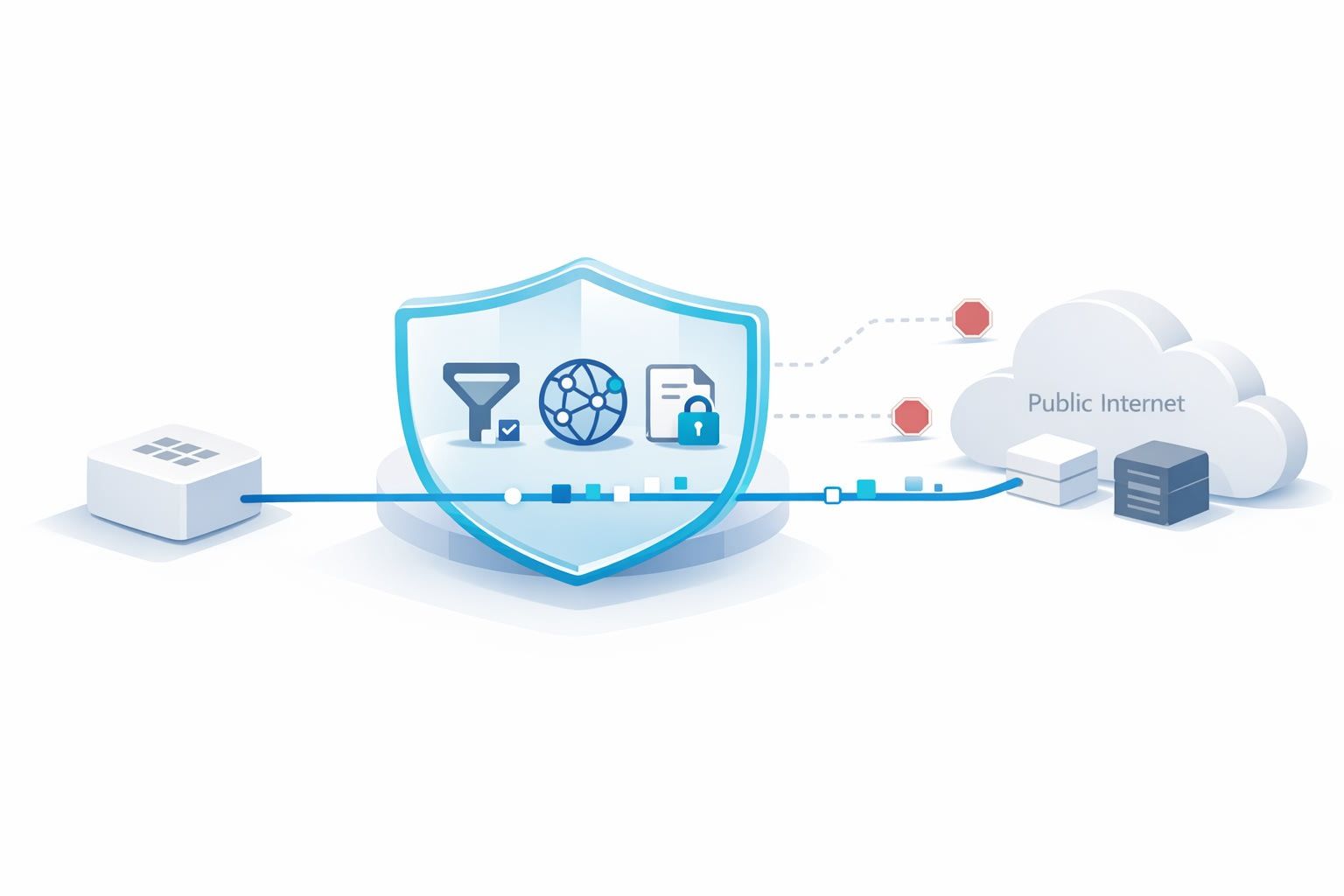
Layer 3 DLP at the edge to reduce what can leak even to allowed endpoints
Even with perfect allowlists, you still have legitimate outbound calls that may carry sensitive text. Edge DLP focuses on content inspection and data minimization so that an allowed call doesn’t automatically mean “anything goes.”
What to detect and control
- Identifiers: emails, phone numbers, national IDs, customer numbers.
- Secrets: API keys, tokens, private keys, credentials in code blocks.
- Regulated data: depending on your industry, include healthcare, financial, or student data patterns.
- Proprietary text: internal-only phrases, document classifications, or watermark strings.

What actions to take
- Block for high-confidence matches (e.g., private keys).
- Redact for partial sensitivity (mask customer identifiers but allow the request).
- Quarantine and require approval for ambiguous cases (useful for prompts that include large pasted documents).
- Log with minimized content so your security team can investigate without creating a second data leak in the logs.
Putting it together as an egress “assembly line”
A practical architecture applies controls in sequence:
- DNS gate: resolve only approved domains; log all queries.
- HTTP egress policy: allow only approved hostnames/paths/methods by workload identity; enforce auth and size rules.
- DLP inspection: detect and act on sensitive content before it exits.
- Observability: central logs with correlation IDs (prompt/run/tool call), plus alerts on policy violations and new destinations.
The operational goal is that developers can add a new tool integration, but it won’t work in production until it has: (a) an approved DNS destination, (b) an approved HTTP policy, and (c) a DLP posture appropriate to the data that tool will handle.
Design details that prevent common bypasses
Make the policy aware of tenants and environments
Multi-tenant LLM apps need per-tenant keys, per-tenant allowed destinations in some cases, and strict separation of logs and traces. If you already think in terms of per-tenant secrets and RBAC, the same model applies to outbound controls: identity, policy, and observability should all be tenant-scoped.
Control “secondary egress” from logs and tracing
LLM apps often send more data to observability vendors than to the model itself. Apply DLP rules to telemetry exporters, enforce payload size limits, and standardize what fields are allowed to be captured from prompts and retrieved documents.
Plan for vendor changes without reopening the floodgates
Model endpoints and tool providers change over time. Avoid “*.vendor.com” allowlists where possible; prefer narrower hostnames and explicit paths. When you must allow a broader domain, compensate with DLP and strict request shaping.
What to measure so safe egress stays effective
- New destination rate (per week) and time-to-approval for legitimate requests.
- Blocked events by reason (DNS deny, HTTP policy deny, DLP match).
- Top tools by outbound volume to spot unexpected data movement.
- Policy drift: exceptions added without expiry, or allowlists widened over time.
These metrics keep the egress layer from becoming either too strict (teams bypass it) or too permissive (it stops being protective). In practice, the best safe-egress programs treat policy maintenance like product work: tight feedback loops, clear ownership, and a bias toward reducing exceptions rather than accumulating them.